

AI and the Law (Part III) - Algorithmic Bias Is Good For You
(Note: This is the third part of a series of posts that were based on several conversations with lawyers and executives about AI, the nature of technology and its application to business problems. The second part is here. Warning: Cultural references are sprinkled left, right and centre. You’ve been warned.)
This post is about bias in Artificial Intelligence, what it is, what it isn't and why it's a feature and not a bug. Scary looking headlines appear in the press about AI taking over people's job, shouts of silicon valley being ethically lost, machines taking over the world or generally making a mess of things. Concerns about algorithmic unfairness are not unfounded, but the same remedies that we’ve previously used to resolve unfairness apply.
Bias Explained
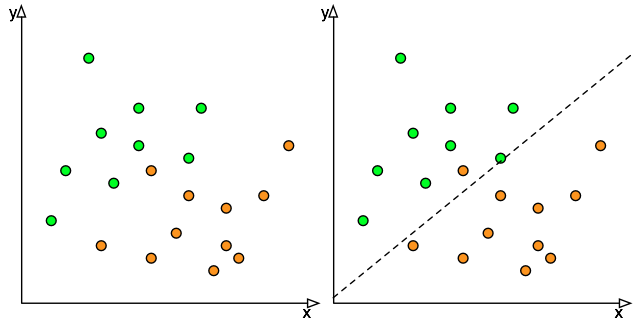 Bias is defined as "prejudice in favour of or against one thing, person, or group compared with another, usually in a way considered to be unfair", yet in the AI and mathematical context bias turns out to be something desirable. Figure 1 is the previous classification example from an earlier blog where we have a simple classifier that separates the orange balls from the green balls. The classifier isn't perfect: it does a reasonable job in most cases but misclassifies one of the oranges balls and there is no way to improve the classifier instance using this linear regression technique because no straight line will separate the green balls from the orange balls.
Bias is defined as "prejudice in favour of or against one thing, person, or group compared with another, usually in a way considered to be unfair", yet in the AI and mathematical context bias turns out to be something desirable. Figure 1 is the previous classification example from an earlier blog where we have a simple classifier that separates the orange balls from the green balls. The classifier isn't perfect: it does a reasonable job in most cases but misclassifies one of the oranges balls and there is no way to improve the classifier instance using this linear regression technique because no straight line will separate the green balls from the orange balls.
However, let's say that the orange balls represent some outcome that is really negative. Like a cancer going undetected or a critical failure in an engine not being reported, the impact of making that wrong classification is disproportionate with someone having to go through an unnecessary biopsy or the machine being shutdown for unwarranted preventive maintenance. Since the cost of misclassifying that orange ball is so high, we would rather have additional misclassified green balls rather than miss one of the orange ones. That process of deliberately preferring one class over another one is called bias.
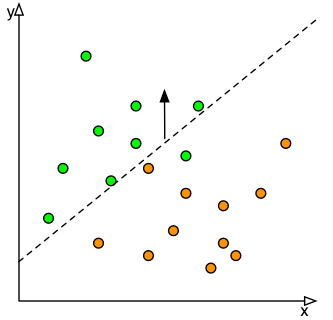 Figure two is a graphical representation of this process. Mathematically, if the linear regression is represented by y = mx + b, we increase the value of b so that all orange balls are below the classification threshold. In practice, classification is never perfect and even the application of an extreme bias may still result in an unsatisfactory condition. However it provides a risk mitigating mechanism that can be quantified based on the expected costs/benefits of each outcome and the classifier that is available.
Figure two is a graphical representation of this process. Mathematically, if the linear regression is represented by y = mx + b, we increase the value of b so that all orange balls are below the classification threshold. In practice, classification is never perfect and even the application of an extreme bias may still result in an unsatisfactory condition. However it provides a risk mitigating mechanism that can be quantified based on the expected costs/benefits of each outcome and the classifier that is available.
Let's say you are using the classifier to route incoming forms to one of two offices for processing, office green and office orange. Office orange has a single clerk whose processing of the form is clerical, office green involves a review committee of five people who must review the form in depth. Assume that the time needed to send a misrouted form back to the other office is the same in each case. The cost of a form misrouted to the office green is thus five times more than office orange since it is taking up the time of five people concurrently. To mitigate the cost of misrouted forms, the classifier will be biased to favour the green office slightly over the orange office, calculated based on the estimated number of green and orange forms and the relative costs of misrouted orange and green forms. This optimized classified allows us to mitigate the risks of the situation using AI and not the other way around.
"Plus ça change, plus c'est la même chose"
So why are people so concerned about bias? It's the possibility of having one's autonomy restricted by a machine without recourse. Office Space's PC LOAD LETTER or "Computer Say No" jokes aside, the risks of AI are no different than that of other technologies. The perception is that algorithms are somehow biased against ethical principals have been fuelled by everyday examples such as Google auto-tagging black people as gorillas or Google Street View's privacy filter failing to blur out someone’s face. But in the final analysis, the AI is executing what humans programmed it to do. AIs are not autonomous, they act as agents of a person or organizations. Speculation about the liability issues of software borne decisions was covered in a well written article by John Kington [1] in the context of current laws: essentially it comes down to whether the product was defective or whether it was being operated properly.
Unfairness and biases against certain social groups are nothing new and we’ve developed regulatory frameworks to deal with them. But these are human rights that need a human being to make them happen (interestingly, AI works both ways: it can be trained for look for algorithmic unfairness using the same machine readable data). Redlining, the process of ignoring or promoting services to certain communities based on their physical location is still an ongoing problem today and as long as there is an economic motivation for doing so, it will be necessary to have regulatory enforcement effort on it. Whether the redlining is the result of an unethically trained AI or an unethically planned massed mailing is irrelevant: a person made it happen.
The possibility of an AI within an organization becoming sentient and achieving their own agency through (il)legal and financial maneuvering is something that will likely remain with Altered Carbon characters for years to come. Efforts to somehow embed ethics into machines date back to 1942, remember the law of Robotics by Isaac Asimov? Three-quarters of a century later, robots are still dumb as a fence-post, do repetitive labour and whenever a human gets injured, it’s because someone wired the emergency stop button wrong or didn’t lockout the controller. Contrast this with another science fiction scenario: instruct a computer system with contradictory and irreconcilable information, neglecting an Emergency Stop button resulting in the machine murdering its human crew. Humanity has already achieved this: it's called an industrial accident. They happen daily and we have an entire ecosystem of organizations who work to prevent them from occurring: the safety and ethical principals are the same whether the machine runs on electricity, hydraulics or pneumatics.
Toy problems with a strong moralistic implication make for a great book, magazine article or panel discussion topic. They don’t map well to operational planning or real life situations for two reasons: a) emergencies occur because of a number of concurrent failures and b) by their nature they are unplanned. By the time an AI, and we are talking about one that would need to be very sophisticated, has actually formulated the problem, the emergency will likely have resolved itself. Will AI really have to choose between two immoral choices? Not in the near future, primarily because AI isn’t all that smart to begin with and there’s a finite amount of computing power to work with. Ethical decisions require a lot of contextual information, processing and are algorithmically ill-behaved even if you know what the “right decision” is. The self-driving car isn’t going to choose between the baby or grandma [2], it’s going to choose the path with the longest braking distance, because it is the simplest, fastest and most reliable metric to acquire and make a safe decision with.
Lastly, whenever people talk about algorithmic bias or AI bias, they usually mean an error. Coming back to the google gorilla story, it was an error: classify hundreds of millions of images every year and you’ll eventually make an embarrassing decision eventually. Same for people: sit a person at a chair and have them classify images of traffic light and tombstones every day and eventually they will make an error, either by inattention or due to terminal boredom.
The actual reasons that unintentional AI training bias occurs is bad training data and/or the repurposing of an engine whose design goals are misaligned with the current objective. Generating training data is expensive, time consuming and a little back and forth is needed to get the system working properly. An efficient means of creating training data isn’t always available. Graduate students trying to test things scour their research department for training data (old emails, mugshots, sound bytes) and invariably end up drafting their friends and acquaintances which creates a bias all of its own. Good enough for academic testing, those models are sometimes coop’ted by cash starved startups. Similarly, there are limited code bases available for each artificial intelligence methodology. Whatever optimization was built in and long forgotten may have unintended consequences when used for a different application. Careful with that axe Eugene.
Why do we really need AI?
It is a fair question. Why should we use AI when we could be using people to do the work and generate employment? Irrespective of the market forces that effect the labour costs, the fact is that the rate at which we generate information is many times greater than that at which we are capable of processing it. Or, as every parent will tell you, the capacity of a 5 year old to ask questions is wildly disproportionate to theirs parents combined capacity to answer them all. Part of the problem is human beings: we haven't changed much since Julius Caesar crossed the Rubicon but our society has changed dramatically: only a very few of the people reading this will remember a world without the internet where just getting the phone number for someone out of town was a serious information search. Our capacity to personally process information has not kept up with the dramatic increase in data.
Getting more people to process the information is also not an answer: as more people enters the system, they themselves generate more information and the situation becomes a vicious circle. According to a popular quote from Google's CEO, every 48 hours humankind creates more data than it did before 1993. There is no catching up with current methods. Our current approaches to data management have resulted in some embarrassing responses [3] to ATIP requests with estimates of over 80 years! It is obviously not acceptable for straightforward information requests not to be answerable within the lifetime of a human being.
The only real viable solution is cognitive automation through AI. There has been much research on information retrieval and question answering over the years, most it comes from an age where the rarity of data made finding what you were looking for easy. Studies about how human beings handle information has revealed that we aren’t really good at it: attempting to create gold standard classification sets at the American National Insitute of Standards revealed that for non-trivial tasks, people are only accurate 40% of the time [4][5]. Using reviewing panels, multiple accessors and some statistical tricks, the precision / recall curve can only be risen to 65% at 65%. This means that careful thinking about accuracy should be done when using both AI and people: AI’s are great at making simple decisions over and over again while humans do better at decision that require a lot of context.
An example that I like to use is the most important business meeting of your life. You’ve locked the office door, unplugged the phone, turned off the cell phone and made everyone swear that they wouldn’t disturb you. When your spouse has a car accident, calls from the emergency room payphone with your child going in for emergency surgery, your colleague will charge into your office to tell you to take the call. The AI will do what you asked and leave you alone. The value of people is that they have judgement, AIs don’t.
Conclusion
Artificial Intelligence is here to stay and at the pace that things are going, necessary for our civilization to keep functioning. As with any new tool, reading the safety warnings and the manual is a good idea. Writers, wether academic, press or science fiction, tend to play up the good story, predict exciting situations that can end up in gloom and doom. But the reality is that to work well, AI projects need to be focused on a single problem and well tested. The thoughts of skynet, or the War Games WOPR, taking over NORAD computers is a good movie plot, but it won’t happen anytime soon.
References
- , “Artificial intelligence and legal liability”, in International Conference on Innovative Techniques and Applications of Artificial Intelligence, 2016.
- , “Should a self-driving car kill the baby or the grandma? Depends on where you’re from”, Technology Review, 2018.
- , “Your document request will be fulfilled by 2098”, The Toronto Star, Toronto, Ontario, 2018.
- , “What we have learned, and not learned”, The BCS/IRSG 22nd Annual Colloquium on Information Retrieval Research, pp. 2-20, 2000.
- , “Overview of the TREC 2011 legal track”, in Proc. 20th Text REtrieval Conference, 2010.